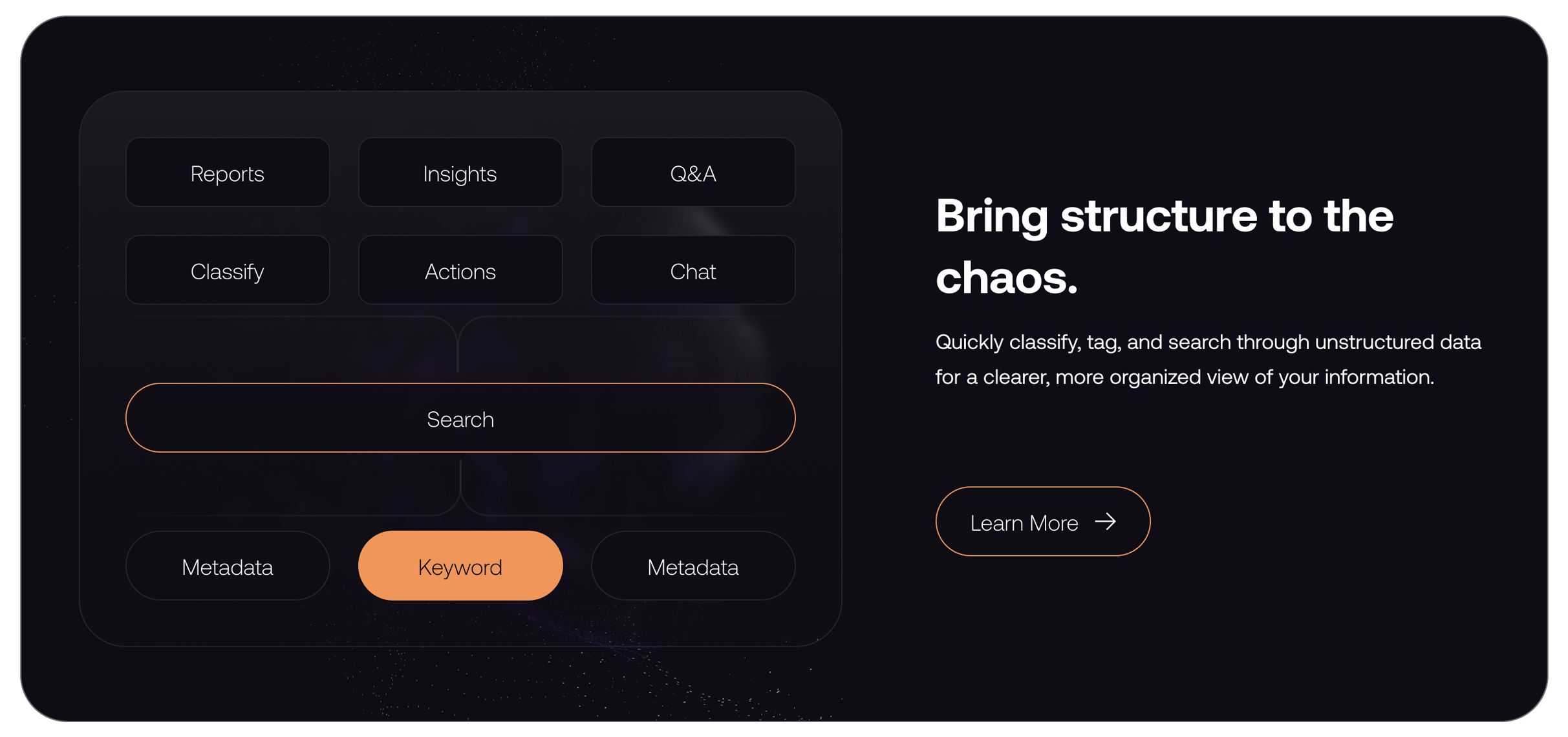
Data Normalization
Standardize and organize disparate data formats for consistent, actionable insights.

Most tools work only in the cloud or on-premises, leaving gaps in visibility and control.
Tagging and sorting data without intelligent automation takes far too much time.
Cleaning, migrating, and optimizing data often still requires external tools and workflows.

Standardize and organize disparate data formats for consistent, actionable insights.
Automatically tag and categorize data for improved searchability and compliance tracking.
Operate across any cloud platform with complete flexibility and independence.
Access and analyze your data wherever it resides, without the need for costly migrations.
Manage multiple clients or departments seamlessly within a single, secure platform.
Tailor data classifications to meet your specific organizational or regulatory needs.
See how we integrate with your existing tech stack.
Of enterprise data is unstructured
Of data lives in a hybrid cloud of multi-cloud environment
Of unstructured data is growing annually
Of unstructured data is growing annually
Of companies have a problem with unstructured data management
Of IT decision-makers worry their infrastructure can’t handle increasing future data demands
Aparavi is a set of tools that allow you to identify data concerns across your environment, both in the cloud and onprem. It can identify files or emails that contain specific keywords or structures, are stored in insecure locations, or are duplicated in multiple locations. Aparavi allows the adminstrator to define classifications and rules to tag data for later processing such as deletion, archival, or future research.
Aparavi applications classify and tag your data without moving, copying, or changing the data in any way. Aparavi crawls your servers, parses each file, and stores the file attributes including size information, permissions, and standard and custom classifications in the Aparavi system. This data can then be used to identify permission issues, PII or Health Info in the wrong place, find files which meet certain criteria, or any other set of rules you might define.
Aparavi can process any document you have access to – whether they are documents located in Azure or S3, emails on an Exchange Server, Google documents in a Google Workspace account, or anywhere else – if you can point Aparavi to the system, we can handle the documents. Aparavi can read and parse MS Word and Google Docs, Adobe PDF documents, Text and CSV files, MS Excel and Google Sheets, Exchange, Outlook and Google Workspaces emails, Zip files, Images, and more – in fact – Aparavi supports every modern file extension (over 1700 file types). With most document types, it can open and “read” the data in the document, as well as handle the file attributes.
Aparavi lets the Aparavi administrator connect any of your data systems (OnPrem network, Azure, S3, Google Workspace, Exchange, etc). Once connected, Aparavi will crawl through those systems parsing and learning about your data.

351 3rd Street Promenade #300
Santa Monica, CA 90401
(380) 223-9983
Solutions
Blog
Contact Us
Get Started