
The General Text preprocessor node splits unstructured or semi-structured text into smaller document chunks suitable for indexing, embedding, or LLM input. It supports table and plain text formats and applies configurable splitting logic for optimal text segmentation.

Key capabilities
- Text normalization and cleaning
- Configurable document segmentation
- Support for specialized formats (Markdown, LaTeX)
- Language-aware splitting options
- Custom splitting logic
Configuration
When setting up the General Text node, you’ll need to configure several parameters:
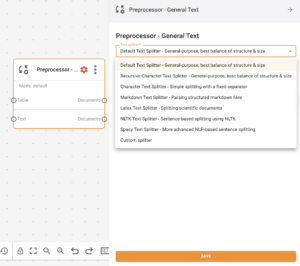
- Splitter Type: Choose the appropriate splitting algorithm based on your text format and needs
- Chunk Size: Set the desired size of text segments
- Chunk Overlap: Configure how much text should overlap between segments
Inputs and Outputs
Input Channels
- Text: Unstructured or semi-structured free-form text for processing
- Documents: Document objects containing text to be preprocessed
- Table: Structured data in table format (ex CSV or tabular JSON)
Output Channels
- Text: Preprocessed text content
- Documents: List of segmented text blocks as structured documents
Splitter Types
| Splitter Type | Description | Best For |
|---|---|---|
| Default Text Splitter | General-purpose splitter that provides the best balance of structure and size | Most use cases |
| Recursive Character Text Splitter | Splits text recursively by different separators | Complex documents with hierarchical structure |
| Character Text Splitter | Splits text based on character count | Simple text segmentation |
| Markdown Text Splitter | Specialized for processing Markdown-formatted text | Documentation, README files |
| Latex Text Splitter | Designed for handling LaTeX document structures | Academic papers, scientific documents |
| NLTK Text Splitter | Uses Natural Language Toolkit for linguistically-aware text splitting | Natural language processing tasks |
| Spacy Text Splitter | Leverages Spacy NLP library for advanced linguistic processing | Advanced NLP applications |
| Custom Splitter | Allows for user-defined splitting logic | Specialized formats and requirements |
Common Use Cases
Text Preparation
- Prepare documents for embedding or vector storage
- Break down large texts into manageable chunks for LLMs
- Segment documents while preserving semantic relationships
- Process diverse text sources for unified downstream handling
Performance Considerations
- Lemmatization is more resource-intensive than stemming
- Processing very large documents may require batch processing
- Consider memory usage when processing large volumes of text
- Balance chunk size with context requirements for downstream tasks
Frequently Asked Questions
- Why is my text processing so slow?
Disable resource-intensive options like lemmatization when processing large volumes of text.
- How do I prevent losing important information during processing?
Adjust settings to preserve critical content, such as keeping numbers for financial text analysis.
- What should I do if I’m experiencing memory errors?
Process your text in smaller batches to reduce memory usage.
Additional Resources
spaCy Tokenization Documentation
Pinecone: Text Chunking Strategies for Vector Search