
The Chonkie Preprocessor integrates advanced text chunking capabilities into the Aparavi workflow. It offers multiple intelligent chunking strategies for optimal document processing and text data segmentation.

Key Capabilities
- Multiple intelligent chunking strategies
- Advanced semantic processing options
- Neural network and AI-powered chunking
- Flexible configuration for different document types
- Integration with Gemini and other models
Configuration
When setting up the Chonkie Preprocessor, you’ll need to configure several parameters based on your chosen chunker:
- Chunker Type: Select the appropriate chunking algorithm based on your text structure and requirements
- Model Selection: Choose the appropriate model for neural or semantic chunkers
- Chunk Parameters: Configure minimum characters, similarity thresholds, and other chunker-specific settings
Supported Chunkers
| Chunker Type | Description | Best For |
|---|---|---|
| RecursiveChunker | Rule-based text splitting | Structured documents with clear boundaries |
| SemanticChunker | Embedding-based similarity splitting | Maintaining semantic coherence in chunks |
| LateChunker | Combined recursive and semantic approach | Optimal results with both rule-based and semantic splitting |
| SDPMChunker | Semantic Document Partitioning Model | Advanced semantic chunking with skip windows |
| NeuralChunker ⭐ NEW | AI-powered neural network chunking | High-quality chunking using pre-trained neural models |
| SlumberChunker ⭐ NEW | Genie-powered intelligent chunking | LLM-assisted intelligent text splitting |

Configuration Examples
-
NeuralChunker Configuration
The NeuralChunker utilizes a pre-trained neural model to split text intelligently. Configure with model selection, device mapping, minimum characters per chunk, mode, and string length parameters.
Basic NeuralChunker Usage: Initialize the NeuralChunker with model parameters and process your text documents.
-
SlumberChunker Configuration
The SlumberChunker uses Google’s Gemini model to intelligently split text. Configure with Genie model, tokenizer settings, candidate size, minimum characters, verbosity, mode, and string length parameters.
Basic SlumberChunker Usage: Initialize GeminiGenie and SlumberChunker with appropriate parameters and process your text documents.
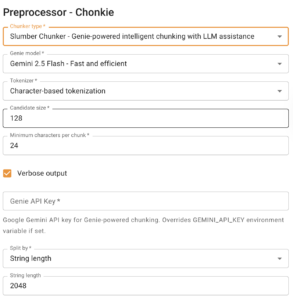
API Key Setup
For SlumberChunker to work, you need a Gemini API key:
-
Option 1: Environment Variable
Set the GEMINI_API_KEY environment variable.
-
Option 2: In Code
Initialize GeminiGenie with your API key.
Troubleshooting
NeuralChunker Issues
- “accelerate” error: Install with the appropriate accelerator package
- Memory issues: Use CPU for lower memory usage
- Model loading: The default model will be downloaded automatically
SlumberChunker Issues
- API key error: Set GEMINI_API_KEY environment variable
- Network issues: Ensure internet connection for Gemini API calls
- Rate limiting: Consider using a different Gemini model if hitting rate limits