
Comprehensive AI-powered workflow for extracting, transcribing, summarizing, and analyzing content from various file types using Gemini LLM
Tutorial Video
Pipeline Overview
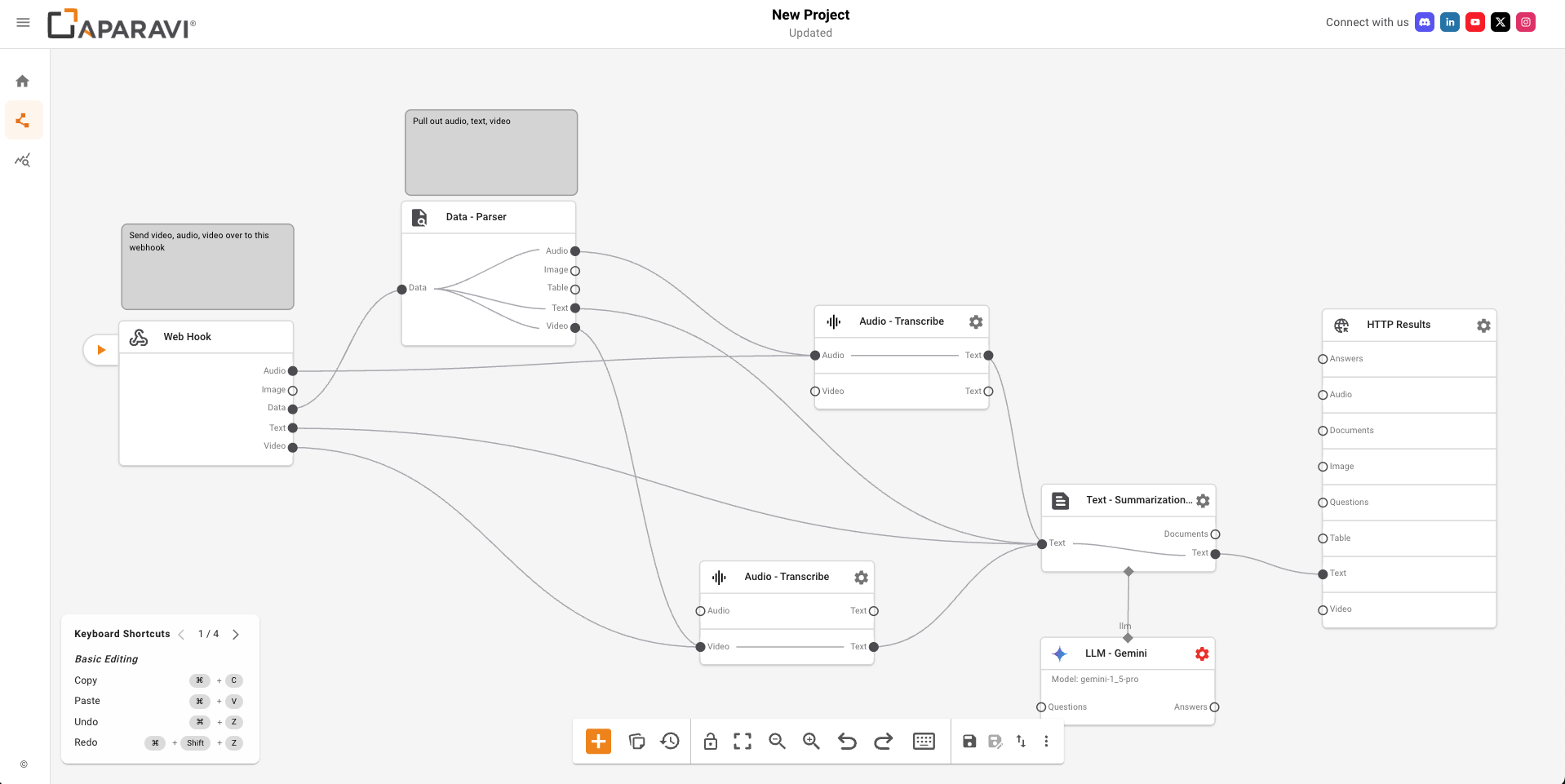
Pipeline Components
🌐 Web Hook
Receives uploaded files via HTTP
⚙️ Parse/Process/Embed
Extracts and processes document content
🎵 Audio – Transcribe
Converts audio/video to text (when applicable)
🧠 Text – Summarization: LLM
Creates intelligent summaries using Gemini
📤 Response
Returns structured JSON output
How to Use the Pipeline
Start the Pipeline
- Run your pipeline in the Aparavi Engine
- Look for the Webhook URL message in the Project Log
- Copy the webhook URL (e.g.,
http://localhost:8080/webhook/...)
Configure API Testing Tool
We recommend using Talend API Tester for easy testing:
- Download: Talend API Tester Extension
- Alternative: Postman, curl, or any HTTP client
Request Configuration
| Field | Value | Description |
|---|---|---|
| Method | PUT |
HTTP method for file upload |
| URL | Your webhook URL | The URL from Step 1 |
| Content-Type | Auto |
Automatically set based on file type |
| Authorization | Your API key | Found in the webhook URL parameters |
Body Configuration
- Type:
File - Upload Method: Drag & drop or click to browse
- Supported Formats: PDF, DOC, DOCX, TXT, MP3, MP4, and more
Send and Process
- Upload your file to the request body
- Click “Send” to submit the request
- Wait for processing (typically 10-30 seconds)
- Check response status:
✅ 200 OK
Success❌ Error codes
Check file format and size
Extract Results
Response Structure
{
"data": {
"objects": {
"cce2fa78-f7fb-5a2e-b391-7c896aeda5cf": {
"text": "Your processed content here..."
}
}
}
}Extracting Content
- Open the response JSON
- Navigate to:
data/objects/[object-id]/text - Copy the text content – this is your processed output
Component Details
1. Web Hook Connector
Purpose: Receives HTTP file uploads and triggers pipeline processing
Configuration:
- Protocol:
webhook:// - Class Type:
source - Capabilities:
noinclude - Register:
endpoint
Supported Input Types: tags, text, audio, video, image
2. Parse/Process/Embed Connector
Purpose: Extracts content from various document formats and prepares for processing
Configuration:
- Protocol:
autopipe:// - Class Type:
other - Capabilities:
internal - Register:
filter
3. Audio – Transcribe Connector
Purpose: Converts audio and video content to text using Whisper models
Configuration:
- Protocol:
audio_transcribe:// - Class Type:
audio - Register:
filter
Model Options
| Model | Speed | Accuracy | Use Case |
|---|---|---|---|
| Tiny | Fastest | Lowest | Quick processing |
| Base | Fast | Low | General use |
| Small | Medium | Medium | Balanced |
| Medium | Slow | High | Quality focus |
| Large | Slowest | Highest | Best quality |
4. Text – Summarization: LLM Connector
Purpose: Creates intelligent summaries, key points, and entity extraction using Gemini LLM
Configuration:
- Protocol:
summarization:// - Class Type:
text - Register:
filter - Invoke: Requires LLM connection
Configuration Options
| Setting | Description | Default |
|---|---|---|
| Number of Summaries | Chunks to summarize after document split | Optional |
| Summary Words | Words per summary (0 = disabled) | Optional |
| Key Point Words | Words per key point (0 = disabled) | Optional |
| Entities | Number of entities to extract (0 = disabled) | Optional |
5. Response Connector
Purpose: Returns structured JSON responses with processed content
Configuration:
- Protocol:
response:// - Class Type:
target - Register:
filter
Supported File Types
📄 Documents
- PDF (.pdf)
- Microsoft Word (.doc, .docx)
- Text Files (.txt)
- Rich Text (.rtf)
🎵 Media Files
- Audio: MP3, WAV, M4A, FLAC
- Video: MP4, AVI, MOV, MKV
- Images: JPG, PNG, GIF, TIFF
📊 Other Formats
- Presentations: PPT, PPTX
- Spreadsheets: XLS, XLSX
- Web Content: HTML, XML
Error Handling
Common HTTP Status Codes
| Code | Meaning | Solution |
|---|---|---|
| 200 | Success | ✅ Processing completed |
| 400 | Bad Request | Check file format and size |
| 401 | Unauthorized | Verify API key |
| 404 | Not Found | Check webhook URL |
| 500 | Server Error | Restart pipeline |
Troubleshooting Tips
- File Size: Ensure files are under 100MB
- Format: Use supported file types
- API Key: Verify authorization header
- Pipeline: Ensure all components are running
- Network: Check connectivity to webhook endpoint
Performance Considerations
Processing Times
| File Type | Size | Estimated Time |
|---|---|---|
| Text Document | < 1MB | 5-10 seconds |
| PDF Document | 1-10MB | 10-30 seconds |
| Audio File | 5-30 minutes | 30-60 seconds |
| Video File | 1-10 minutes | 1-3 minutes |
Security and Authentication
API Key Management
- Location: Found in webhook URL parameters
- Format: Long alphanumeric string
- Security: Keep private and secure
- Rotation: Change regularly for production use
Request Validation
The pipeline validates:
- File format compatibility
- File size limits
- API key authenticity
- Request method (PUT only)