
This pipeline connects your documents to AI language models, creating a system that answers questions based on your specific information. It works by finding relevant parts of your documents when asked a question, then using those parts to create accurate answers that reflect what’s in your files rather than generic knowledge.
Pipeline Overview

This is a Retrieval-Augmented Generation (RAG) pipeline using Qdrant as the vector store and LLM (e.g., Gemini).
| Node | Function |
|---|---|
| Aparavi Sample Data | Pulls raw files from a Drive or documentation repository |
| Data Parser | Extracts plain text from each input file |
| Preprocessor | Cleans and splits text into manageable segments (documents) |
| Embedding Transformer | Converts documents (and separately, questions) into vector embeddings |
| Vector Store – Qdrant | Stores embeddings and metadata; retrieves top-N segments by similarity |
| LLM – Gemini | Consumes retrieved context + question to generate a context-aware answer |
| HTTP Results | Returns the generated response back to the chat UI or API endpoint |
Workflow Breakdown:
1. Data Source Node
This node pulls your source files (e.g., Google Drive, S3, local docs).
How it works
- (e.g. Google Drive)
- You click ▶️ on the Aparavi Sample Data node.
- It fetches files from the configured drive path.
2. Data Parser Node
In this node, we extract the content from the files. In this scenario, we are extracting text.
How it works
- Receives “Data” from the Sample Data node.
- Splits into multiple channels: Text, Table, Image, Audio, Video.
3. Preprocessor – General Text
This node splits large text blocks into smaller “documents” ready for embedding. Here, we’ll take the large text segments and split them up into documents that can be embedded.
How it works
- Takes parser output, applies sanitization, chunking, and metadata tagging.
- Emits a stream of document objects.
Configuration:
- It ensures that our documents are split into well-sized, context-preserving segments, optimizing them for embedding and retrieval in your RAG pipeline.

Setting Value/Option Description Text Splitter Default Text Splitter Balances structure and size for general-purpose use Split by String length Splits text based on character count String Length 512 Each segment is up to 512 characters long Text Splitter

4. Embedding – Transformer
The Embedding – Sentence Transformer node is responsible for converting text (such as document segments or user questions) into vector embeddings, which are essential for semantic search and retrieval in a RAG pipeline.
How it works
- Documents transformer: turns each text chunk into a vector.
Configuration:
Available Options:
- Custom model: Use your own pre-trained or fine-tuned model.
- miniAll: A general-purpose model, suitable for a variety of tasks.
- miniLM: Optimized for general use, offering a good balance between performance and speed.
- mpnet: Another high-quality model, often providing strong results on semantic similarity tasks.

5. Vector Store (Qdrant) Node
The Qdrant Vector Store node is critical in a RAG pipeline. It is responsible for storing and retrieving vector embeddings, enabling efficient semantic search and context retrieval for downstream language models.
How it works
-
- Ingests document embeddings + metadata.
- On query, computes similarity between the question vector and stored vectors.
- Returns top-K relevant document segments.
Configuration:

| Field | Example Value | Description |
|---|---|---|
| Type of Qdrant host | Your own Qdrant server | Specifies the Qdrant deployment (local, cloud, or custom server). |
| Host | localhost | The server address where Qdrant is running. |
| Port | 6333 | The port number Qdrant listens on (default: 6333). |
| Retrieval Score | Related | Sets the minimum similarity score for retrieving relevant vectors. |
| Collection | APARAVI | The name of the Qdrant collection used to store and query vectors. |
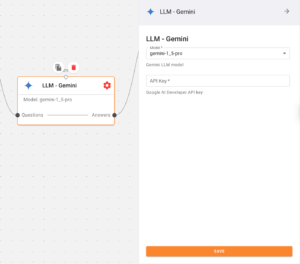
6. LLM – Gemini Node
Generates an answer using the retrieved context and the original question. Here, it sends the question over to the LLM along with the context retrieved from the vector store.
How it works
- Inputs: “Questions” (text prompt) + “Documents” (retrieved context).
- Outputs: “Answers” the LLM’s text response.
Available Models
- Anthropic
- Amazon Bedrock
- OpenAI
- Gemini
- Llama
- XAI
- Ollama
- VertexAI
- DeepSeek
Configuration:
- Here’s where you can find your Gemini API key. Remember to store your API key securely and never share it publicly.
Gemini Config
7. HTTP Results Node
- Receives the generated answer from the LLM node.
- Forward it to the chat UI, API endpoint, or any connected service.
How it works
- Receives “Answers” from the Gemini node.
- Sends them back over HTTP to complete the loop.
Basic RAG Chat Pipeline:
This is a simplified RAG pipeline focused on chat interactions, using Qdrant as the vector store and Gemini LLM.
| Node | Function |
|---|---|
| Chat Input | Receives user questions and chat history |
| Embedding Transformer | Converts user questions into vector embeddings |
| Vector Store – Qdrant | Retrieves relevant document segments by semantic similarity |
| HTTP Result | Returns retrieved documents and question to front-end or next pipeline stage |
Workflow Breakdown B:
1. Chat Input Node
Captures user queries and maintains conversation context.
How it works
- Receives user questions from the chat interface.
- Formats the question for vector embedding.
2. Embedding Transformer
Converts the user question into a vector embedding for semantic search.
How it works
- Receives a formatted question from the Chat Input node.
- Transforms text into a vector representation using the same model used for document embedding.
3. Vector Store (Qdrant) Node
Searches previously stored document embeddings for semantically similar content.
How it works
- Compares the question embedding against stored document embeddings.
- Retrieves the top-K most relevant document segments based on similarity scores.
- Returns both the original texts and their relevance scores.
4. LLM – Gemini Node
How it works
- Inputs: “Questions” (text prompt) + “Documents” (retrieved context).
- Outputs: “Answers” the LLM’s text response.
Available Models:
-
- Anthropic
- Amazon Bedrock
- OpenAI
- Gemini
- Llama
- XAI
- Ollama
- VertexAI
- DeepSeek
Configuration:
- Here’s where you can find your Gemini API key. Remember to store your API key securely and never share it publicly.
Gemini Config
5. HTTP Result Node
Returns the retrieved context to the interface or to a downstream LLM.
How it works
- Packages the original question and retrieved contexts.
- Sends response back to the chat interface or another pipeline for LLM processing.
Hit the Play Button ▶️
Frequently Asked Questions:
Invalid API key:
Verify GEMINI_API_KEY is set and valid.
Endpoint unreachable:
Confirm GEMINI_API_URL is correct and network-accessible.
Vector store unreachable?
Verify Qdrant’s host, port, and firewall rules.