
The advanced RAG pipeline builds two separate vector indexes, one on raw text and one on AI-generated summaries, to power smarter, faster retrieval. It accepts both file data and live chat input, and uses Qdrant as the vector store, plus Gemini (via Ollama) as the final answer LLM.

| Node | Function |
|---|---|
| Aparavi Sample Data | Pulls source files (docs, PDFs, images, audio/video) from Google Drive or S3 |
| Chat Input | Captures user questions or prompts via a chat interface |
| Data Parser | Splits each file into Text, Table, Image, Audio, and Video streams |
| Text Summarization | Uses a VertexAI LLM to create concise summaries of parsed text |
| Preprocessor – General Text | Cleans & chunks raw text (and separately, summary text) into ~512-char “document” objects |
| Embedding – Transformer (Raw & Summ.) | Converts both raw‐text chunks and summary‐text chunks (plus incoming questions) into vector embeddings |
| Vector Store – Qdrant (Full Index) | Stores raw-text embeddings; retrieves top-K full‐text segments |
| Vector Store – Qdrant (Summary Index) | Stores summary embeddings; retrieves top-K summary segments |
| LLM – Gemini | Takes user question + retrieved full-text & summary context to generate a final, grounded answer |
| HTTP Results | Returns the LLM’s response to your chat UI or API endpoint |
Workflow Breakdown:
1. Data Source Node
How it works
(e.g., Google Drive)
- Click ▶️ on the Aparavi Sample Data node. You’ll see two options in the Files section.
- The node fetches files from the configured drive path when you select ‘Preselected Data Sets.’
- If you select ‘Custom Data sets,’ you’ll need to provide the sample data path in the text box.
- Learn more about the Google Drive source node here: link
2. Data Parser Node
How it works
- Receives “Data” from the Sample Data node.
- Splits into multiple channels: Text, Table, Image, Audio, Video.
3. Dual‐Branch Indexing
This pipeline creates two parallel embedding-retrieval branches for comprehensive context retrieval.
How it works
- Creates separate vector stores for raw text and summaries
- Improves retrieval by capturing both detailed content and semantic concepts
3 A. Raw‐Text Branch
Components:
- Preprocessor – General Text
Cleans & chunks the parsed Text into ~512-char documents. - Embedding – Transformer (Raw)
Converts those text chunks into high-dimensional vectors. - Vector Store – Qdrant (Full Index)
Ingests raw-text embeddings + metadata. On query, returns the top-K most similar document segments.
3 B. Summary Branch
Components:
Text Summarization
- Sends parsed Text to an LLM (VertexAI) to produce concise summaries.
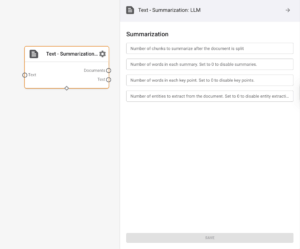
Based on your Cross-Domain Insights project, here are my recommended settings for the Text Summarization node:
| Parameter | Recommended Value | Rationale |
|---|---|---|
| Number of chunks to summarize | 5-7 | Balances comprehensive coverage with processing efficiency for your cross-domain data |
| Words in each summary | 150-200 | Detailed enough to capture relationships between employee, financial, and customer data |
| Words in each key point | 30-40 | Sufficient to extract meaningful connections across domains |
| Entities to extract | 15-20 | Captures important people, projects, metrics, and concepts across your varied datasets |
These settings are optimized for discovering cross-domain relationships between employee profiles, financial records, and customer feedback as mentioned in your project description.
Components:
- Preprocessor – General Text
Cleans & chunks the parsed Text into ~512-char documents. - Embedding – Transformer (Raw)
Converts those text chunks into high-dimensional vectors. - Vector Store – Qdrant (Full Index)
Ingests raw-text embeddings + metadata. On query, returns the top-K most similar document segments.
4. Embedding – Transformer

How it works
- Embedding – Transformer (Questions)
Encodes the incoming Question into a vector, using the same model as above.
5. Vector Store – Qdrant (Full Index)

Both Qdrant indexes (Full & Summary) receive the Question vector:
- Full Index → retrieves relevant raw paragraphs
- Summary Index → retrieves relevant summary snippets
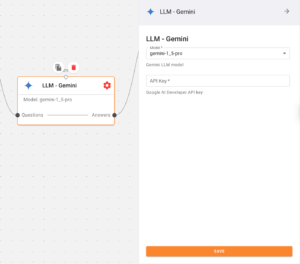
6. LLM – Gemini Node
Generates an answer using the retrieved context and the original question. Here, it sends the question over to the LLM along with the context retrieved from the vector store.
Available Models:
- Anthropic
- Amazon Bedrock
- OpenAI
- Gemini
- Llama
- XAI
- Ollama
- VertexAI
- DeepSeek
Configuration:
- Here’s where you can find your Gemini API key. Remember to store your API key securely and never share it publicly.
Gemini Config
7. HTTP Result Node
Returns the retrieved context to the interface or to a downstream LLM.
How it works
- Packages the original question and retrieved contexts.
- Sends response back to the chat interface or another pipeline for LLM processing.
Hit the Play Button ▶️
Frequently Asked Questions:
-
Why use a dual-index approach?
The dual-index approach (raw text + summaries) provides both detailed context and high-level concepts, improving relevance and reducing hallucination in complex queries.
-
Invalid API key
Verify GEMINI_API_KEY is set and valid in the LLM node configuration.
-
Vector store unreachable?
Verify Qdrant’s host, port, and firewall rules. Make sure both vector stores (Full Index and Summary Index) are properly configured.
-
How to optimize retrieval performance?
Balance between the number of chunks retrieved from each index. For complex queries, increase top-K from the raw index; for conceptual questions, prioritize the summary index.