

From Data Deluge to Strategic Asset: Expert Strategies for Enterprise Data Management
For many organizations, effective data management of unstructured content is a key challenge that directly impacts their ability to scale operations, particularly in AI. According to McKinsey, 72% of leading companies report that managing data effectively is one of their top challenges when scaling AI use cases. The root cause of this issue? Poor data quality, which can hold back business performance and innovation.
Effective data management holds the key to solving this problem. It helps businesses accelerate the delivery of new use cases by 90%, cut technology and maintenance costs by 30%, and mitigate data governance risks.
However, achieving these results requires a deliberate and structured approach to how data is handled and used across the enterprise. This article covers expert strategies that can help organizations transform their data challenges into tangible business advantages.
Codify Governance with Code
Strong data governance empowers organizations to manage data with control, clarity, and confidence at scale. Modern enterprises need governance that adapts as data moves, structured enough to enforce policy, yet flexible enough to evolve with the system.
Advanced Data Governance Frameworks
A strong governance framework begins with specificity that defines what “good data” looks like in operational terms. Customer records need valid email addresses (accuracy), no missing phone numbers (completeness), and consistency across systems. These criteria help operationalize quality standards within broader data management efforts.
Maturity happens in stages. Many organizations begin reactively, addressing issues after they arise. But the shift to proactive governance means building checks into ingestion processes, detecting schema drift automatically, and flagging anomalies before they reach downstream systems.
Automated Data Lineage Tracking
If you can’t see how data moves, you can’t trust how it’s used. Automated lineage creates real-time visibility into where data comes from, how it’s transformed, and where it ends up. Instead of relying on tribal knowledge, teams can trace how a dashboard metric was derived, from raw source to final transformation. This matters when issues emerge, but also during audits or internal reviews.
Lineage tracking needs to cover more than just movement to make this work. It should expose transformation logic, security boundaries crossed, and downstream dependencies. This turns lineage into a living map that shows where data came from, how it was shaped, where it’s going, and who it impacts.
Governance as Code (GaC) Implementation
Governance as Code supports scalable data management by embedding rules directly into systems, turning compliance into a continuous, automated process. For instance, a policy that says “PII must be encrypted” is encoded into the pipeline in a way that it blocks unencrypted writes at the storage layer. Similarly, GaC enables organizations to make a requirement like “IDs must follow a canonical format” a validation step during ingestion.
Additionally, GaC helps organizations implement rules that ensure completeness, structural integrity, and lineage retention. These checks run automatically and flag issues in real time, not weeks later.
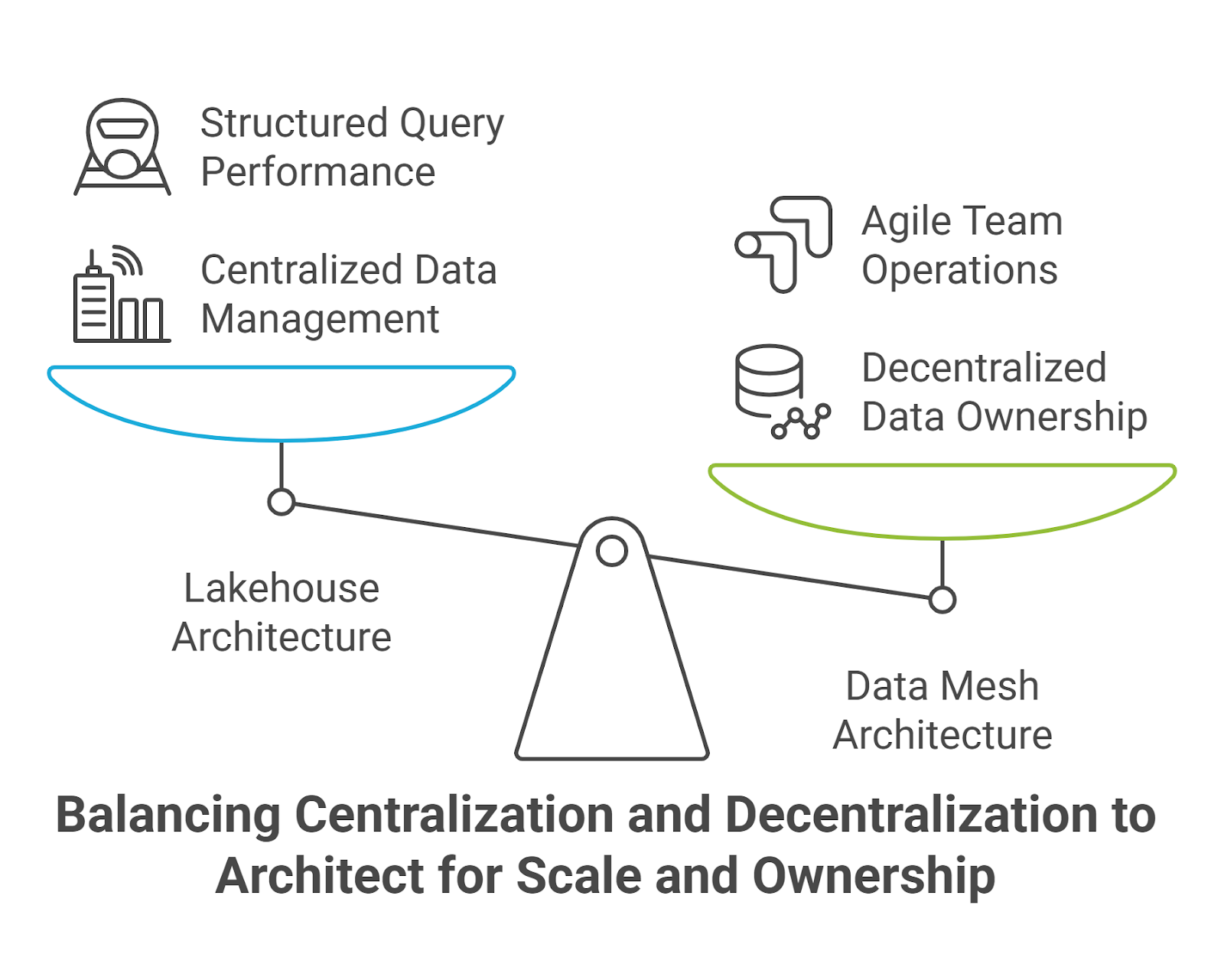
Architect for Scale and Ownership
Scaling enterprise data means balancing flexibility, performance, and control. A multi-tiered data management architecture achieves this by combining two complementary models:
- Lakehouse design
- Domain-oriented data mesh
Lakehouse: Bridging Flexibility and Performance
The lakehouse model merges the scale of data lakes with the structure of warehouses. Traditional lakes store raw, unstructured data but lack support for analytics workflows. On the other hand, warehouses offer strong performance but struggle with scale and schema rigidity.
Lakehouse architecture brings these strengths together, adding schema enforcement, ACID compliance, and SQL query performance directly on top of object storage. This means analysts can run structured queries while data scientists can access raw data, all in one environment without the need for duplication or reshaping.
This model reduces overhead, minimizes data movement, and supports both BI and AI workloads from a single source of truth.
Data Mesh: Scaling Through Decentralization
Architecture addresses technical scale, but organizational structure needs to scale with it. Data mesh supports this by distributing data ownership across domain teams. Each team is accountable for the quality, usability, and life cycle of the data it produces. This product-oriented mindset helps ensure that data is not only collected but also made useful.
Adopting a data mesh involves more than deploying new tools. Domain teams must define their own standards, service-level agreements, and governance policies. Meanwhile, platform teams focus on providing shared infrastructure and interfaces that make decentralized execution manageable.
This division of responsibility leads to greater agility. Teams can operate independently, iterate faster, and deliver data that meets business needs without waiting on centralized coordination.
When combined with a lakehouse architecture, the two approaches work in tandem. The lakehouse centralizes storage and computation. The mesh organizes how people and processes engage with that infrastructure, creating a flexible yet scalable foundation for enterprise data operations.
With the storage structure in place, the next hurdle is operational drag: manual data prep, brittle scripts, and nighttime batch jobs. Machine‑learning‑driven cleaning and orchestrated pipelines remove that drag so data arrives trustworthy and on time.
Automate Cleaning and Flow with ML
Data preparation is often the hidden bottleneck in analytics and AI workflows. Automating this process brings structure to chaos by learning how to clean, validate, and repair data at scale.
Machine Learning for Data Cleaning
Instead of encoding every edge case, machine learning models learn from examples. Given enough history, they can identify inconsistent formats, catch subtle anomalies, and resolve duplicate records without manual intervention. This approach works well for tasks such as entity resolution, outlier detection, and filling in missing values. These are areas where fixed rules often break down, and learned patterns are better suited to handle complexity.
Consider customer address data. A rule might require all ZIP codes to be five digits, but what happens when someone inputs “NY, 10001-4321” or writes “Fifth Ave.” in different formats? A trained model can recognize valid variations, even with typos or partial data, by referencing patterns it has seen before.
Data Pipeline Orchestration
Once data flows, orchestration ensures it moves in the correct order, at the right time. It’s less about processing data and more about ensuring the right systems trigger, wait, and recover when needed.
Effective orchestration coordinates dependencies across ingestion, transformation, validation, and delivery. It includes scheduling logic, monitors for failures, and reroutes tasks automatically when things go wrong.
For example, if one upstream file is delayed, a pipeline that ingests sales data from dozens of sources may fail. With orchestration in place, the system waits for the input or retries automatically without human intervention.
Automation moves data faster than humans can review, widening the attack surface unless security is embedded in every request.
Secure Every Call with Zero‑Trust
Zero-trust architecture verifies every request, limits access to the bare minimum, and protects data at every stage of its lifecycle.
Granular Access Control
Zero-trust starts with granular control. Instead of broad roles, permissions are defined at the attribute level:
- Column-level filtering shows only what’s necessary. For example, a support agent might see a phone number but not the billing history.
- Row-level rules restrict visibility to only what’s relevant, like region-specific data for local managers.
- Cell-level protections go further, masking or redacting sensitive values unless criteria are met. For example, the same record might be displayed differently in finance than in engineering.
- Access is also contextual. Someone logging in from an unknown device outside working hours? Even with credentials, they may be blocked or limited.
End-to-End Encryption
Visibility is just one layer. Zero-trust also demands that data remains protected no matter where it lives or moves:
- At rest, it’s encrypted across structured and unstructured storage systems.
- In transit, it’s secured across internal and external networks.
- In use, sensitive computations happen in isolated environments where data remains shielded during processing.
- At the application layer, encryption persists even if the infrastructure is compromised.
The key is to make encryption the default. Back it with strict key rotation, separation of roles, and enforcement baked into your architecture.
Store Smart: Compress, Partition, Prune
Scaling data requires smarter storage strategies. Format, compression, and partitioning should align with performance needs and access patterns.
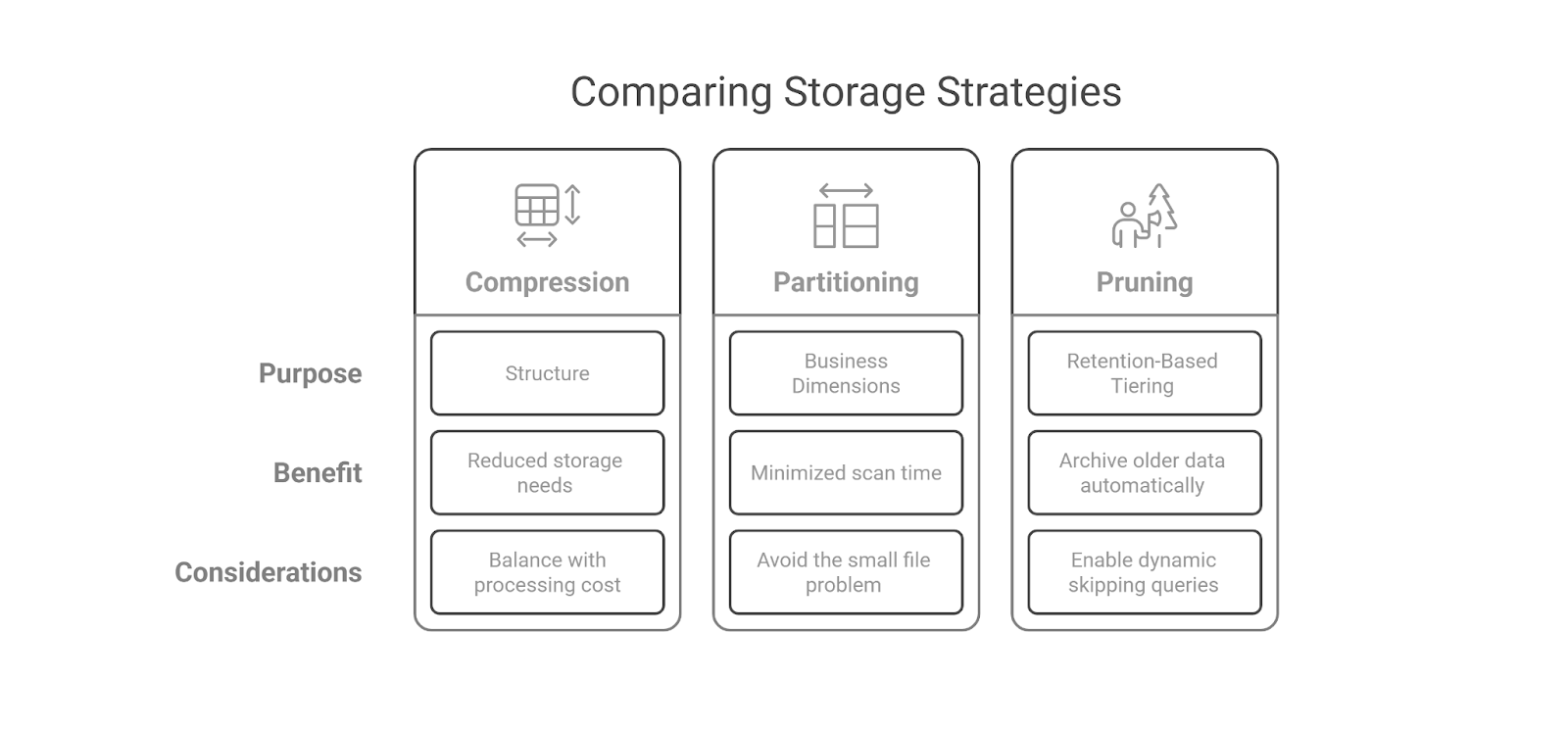
Compress
- Use Columnar Formats for Analytics: Storing data by attribute rather than row improves both query speed and compression. Columnar formats like Parquet or ORC can deliver up to 10x compression compared to row-based alternatives.
- Match Compression to Data Structure: Delta encoding is effective for time-series or slowly changing records. Dictionary encoding is better suited for columns with repeated values, while run-length encoding works well for sparse binary fields. Rather than applying a single method universally, choose based on how the data behaves.
- Balance Storage Savings with CPU Cost: While heavier compression reduces file size, it can increase decompression time. Use lighter compression for frequently accessed data where performance matters more than storage efficiency.
Partition
- Use Business-Aligned Dimensions: Partitioning by time is common, but it’s often more efficient to organize data by meaningful business dimensions such as geography, product category, or customer group. This allows queries to target only relevant slices.
- Avoid Excessive Partitioning: Too many small partitions create overhead and slow performance. Use platforms that monitor distribution and rebalance partitions automatically to maintain efficiency.
Prune
- Enable Dynamic Partition Pruning: Query engines can skip irrelevant partitions at runtime, improving performance for targeted queries. This works best when partition keys align with commonly used filters.
- Tie Partitions to Retention Policies: Link time-based partitions to data lifecycle rules. Older data can be moved to lower-cost storage automatically, simplifying archiving and keeping high-performance storage reserved for recent, active data.
Activate AI with Feature‑Ready Data
Moving AI from prototype to production requires building the data infrastructure that can support AI consistently, at scale.
Automate Feature Engineering with Business Context
Structure feature repositories around real business entities such as customers, accounts, transactions, patients, or claims. This entity-centric design aligns with domain thinking and makes features easier to reuse across teams and models.
When building real-time pipelines, focus on “velocity features” that actually influence predictions. Streaming infrastructure is expensive to build and maintain. Before committing, measure how prediction quality changes with delayed input. If a 30-minute lag yields the same output, micro-batching offers a leaner solution.
Design for Operational Resilience, Not Just Accuracy
Models need to operate in live environments with unpredictable inputs and shifting behavior. That’s why monitoring must link statistical drift with business impact. A shift in data distribution may mean nothing for one application but signal risk for another. Set alert thresholds that reflect operational tolerances, not arbitrary variance.
Operational readiness also requires preparation. Build model runbooks that outline who gets notified during incidents, what diagnostics to run, and when to roll back. Doing so is essential for high-impact systems like fraud detection or pricing engines.
Shadow deployments provide another layer of protection. New models can run silently alongside production, letting teams compare outputs against existing systems in real conditions without risking disruption. This is how you validate behavior, build confidence, and reduce surprises post-deployment.
You can stitch these layers together yourself with open‑source tools, as many enterprises do. But months of integration work delay insight. Aparavi bundles governance hooks, lineage, compression policies, and vector pipelines behind one control plan.
Accelerate All of the Above with Aparavi
Enterprise data estates are sprawling, spanning on-prem, cloud, and SaaS. Aparavi brings order to that complexity through a single platform that classifies, governs, and prepares content for downstream analytics and AI workflows.
Automated Classification with Built-in Intelligence
Aparavi scans over 1,000 file types directly in place, eliminating the need for bulk migration. Its multi-layer engine combines OCR, signature matching, full-text indexing, and pattern recognition within a single pass.
When files match predefined rules, such as those identifying regulated personal data, the system can automatically encrypt, quarantine, migrate, or flag them for review. Teams can define custom taxonomies to fit their business context, and any updates to classification rules immediately trigger reprocessing to keep metadata current.
Centralized Policy Enforcement at Enterprise Scale
A browser-based console allows teams to locate, tag, retain, or delete content across cloud services, on-premises storage, and SaaS environments. Policy bundles can be exported and reused across departments or client deployments.
Encryption is applied both during transit and while data is at rest. Role-based access control integrates with SSO to streamline secure access, while administrative settings let teams adjust performance parameters to align with workload demands.
Integrated Pipelines for AI Use Cases
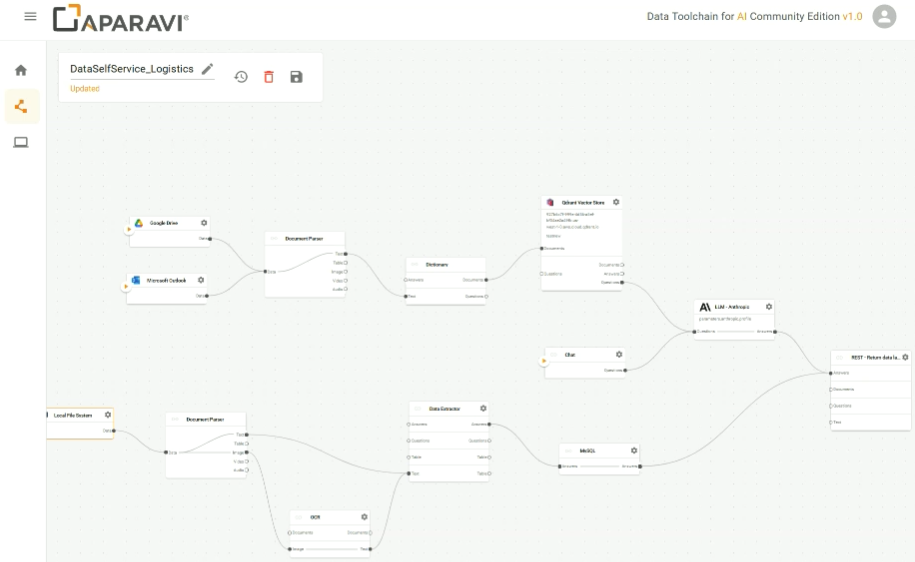
Aparavi provides a visual workflow builder and an API for creating AI-ready pipelines. Files can be parsed, chunked, and embedded before sending the output to vector databases such as Milvus, Qdrant, or Weaviate.
The platform supports embeddings generated by OpenAI and Hugging Face models. The community edition supports up to 5,000 files and 5 GB, making it ideal for early-stage projects. Higher tiers unlock capabilities such as semantic search, embedding customization, and full integration with retrieval-augmented generation pipelines.
Final Takeaway
Unstructured data shouldn’t be treated as background noise. When left unmanaged, it drives up storage costs, stalls AI adoption, and creates compliance blind spots. Organizations that take a deliberate, policy-driven approach see a different outcome. Redundant and low-value content is eliminated, sensitive data is governed in place, and high-value assets are transformed into AI-ready inputs.
Aparavi provides a clear blueprint. Its platform classifies over 1,600 file types in place, automatically applies retention and encryption policies, and converts curated content into vector embeddings that feed directly into GenAI applications. This unified approach improves data quality, reduces operational waste, and accelerates time-to-insight.
Firms that operationalize their data pipelines consistently outperform on efficiency, product velocity, and margin expansion. The signal is clear. Teams that govern and activate unstructured data are better positioned to move fast, scale responsibly, and innovate with confidence.
To see what this looks like in practice, start for free or speak with an expert.