
What does it do?
How do Iuse it?
Add the FireCrawl Web Crawler
- Insert the source node at the beginning of your pipeline
- Configure the target URL and API credentials
- Set up include/exclude patterns to scope the crawling
- Connect the output to downstream processing components
Configure Parameters
The FireCrawl connector requires these configuration parameters:
| Parameter | Description | Required |
|---|---|---|
firecrawl.url |
Site or page URL to scrape | Yes |
firecrawl.apikey |
FireCrawl API key (stored securely) | Yes |
firecrawl.embed_images |
Embed images inline into HTML (default: false) | No |
include/exclude |
Path filters to scope crawling | No |
For more information on how to get the parameters, please look at the FireCrawl Docs.
Connect Output
- Connect the HTML output lane to downstream components
- Each scraped page will be emitted as HTML content with metadata
- Output format is consistent for reliable downstream processing
ConfigurationPipeline
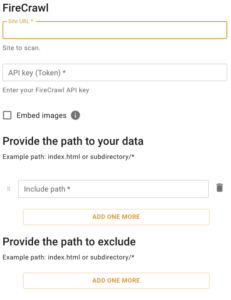
The FireCrawl connector follows a structured configuration approach:
1. URL Configuration
Action: Set the target website or page URL
Purpose: Defines the starting point for web scraping
Example: https://example.com/docs/
2. Authentication Setup
Action: Configure FireCrawl API key
Purpose: Provides access to the FireCrawl scraping service
Format: fc-xxxxxxxxxxxxxxxx
3. Content Options
Action: Set image embedding preferences
Purpose: Controls whether images are inlined into HTML
Effect: Increases payload size but ensures complete content capture
4. Scope Filtering
Action: Define include/exclude patterns
Purpose: Limits crawling to specific site sections
Examples: docs/*, blog/*, !private/*
Example Use Cases
Documentation Indexing
Scenario: Building a searchable index of company documentation
Solution: Crawl documentation sites and feed content to search indexing
Result: Comprehensive searchable knowledge base from web content
Content Classification
Scenario: Automatically categorizing web pages by content type
Solution: Scrape pages and process through ML classification models
Result: Automated content taxonomy and organization
Data Migration
Scenario: Migrating content from legacy websites
Solution: Systematically crawl and extract structured content
Result: Automated content migration with preserved structure
Competitive Analysis
Scenario: Monitoring competitor websites for changes
Solution: Regular crawling to track content updates and changes
Result: Automated competitive intelligence gathering
Best Practices
For Optimal Results
- Use specific include/exclude patterns to limit scope and improve performance
- Test with a small URL set before scaling to full site crawling
- Monitor API usage limits and adjust crawling frequency accordingly
- Consider image embedding only when necessary due to increased payload size
Pipeline Integration
- Place FireCrawl at the beginning of your pipeline as a source
- Connect to text extraction, classification, or indexing components
- Use transformation components to clean or structure the HTML content
- Consider rate limiting for large-scale crawling operations
Performance Considerations
- Crawling speed depends on target site responsiveness and API limits
- Use path filters to avoid crawling unnecessary content
- Monitor bandwidth usage, especially with image embedding enabled
- Implement error handling for unreliable target websites
Technical Details
Behavior and Flow
- stat: Tries a scrape to check reachability; returns False if OK (exists), True otherwise
- checkChanged: Forces a render by setting a fake size
- render: Scrapes via FireCrawl, validates success, optionallyembeds images, sends metadata and HTML to pipeline
What it emits
Supported Actions
export– Extract and process contentdownload– Retrieve and store content locally
Troubleshooting
Common Issues
- 401/403/Invalid key: Ensure
firecrawl.apikeyis correct and has sufficient permissions - 500 “All scraping engines failed”: Double-check
firecrawl.url, try again later, or contact FireCrawl support if persistent - Empty/Unexpected HTML: Check for redirects and site behavior; consider disabling image embedding to reduce payload size
- Network timeout: Verify network access from Engine host to FireCrawl API and target site
Performance Issues
- Large sites may exceed API rate limits – implement appropriate delays
- Image embedding significantly increases processing time and bandwidth
- Complex include/exclude patterns may slow down filtering
- Some servers return 200 for missing pages (redirects) – content is still emitted as returned
Error Handling
- Non-success or non-200 status raises errors like “Failed to scrape URL…”
- Invalid URLs or unreachable sites will cause pipeline failures
- API key issues result in authentication errors
Expected Results
After using the FireCrawl Web Crawler in your pipeline:
- Structured HTML Content: Clean, processable HTML from target websites
- Comprehensive Metadata: URL, path, name, and size information for each page
- Consistent Format: Standardized output suitable for downstream processing
- Scalable Extraction: Efficient crawling of single pages or entire site sections
- Reliable Content Capture: Professional-grade scraping with optional image embedding
Additional Resources
For more information on how to configure, please look at the FireCrawl Docs.