

The Unstructured Data Challenge: Turning Information into Intelligence
Ever feel overwhelmed by the sheer volume of unstructured data? With 80 to 90% of all new enterprise data being unstructured, businesses face the challenge of transforming this unorganized data into something valuable.
Unstructured data exists in various forms, from emails and documents to social media posts, yet it’s often siloed and disconnected from actionable insights. Without the right systems, such data becomes a barrier rather than an asset.
Converting raw, unstructured information into intelligence drives innovation and operational efficiency. Being able to understand this data is key to gaining a competitive edge and predicting things like customer sentiment.
In this article, we’ll go over the strategies that can help your business turn unorganized information into a true competitive advantage.
The Promise of Unstructured Data: Transforming a Liability to an Asset
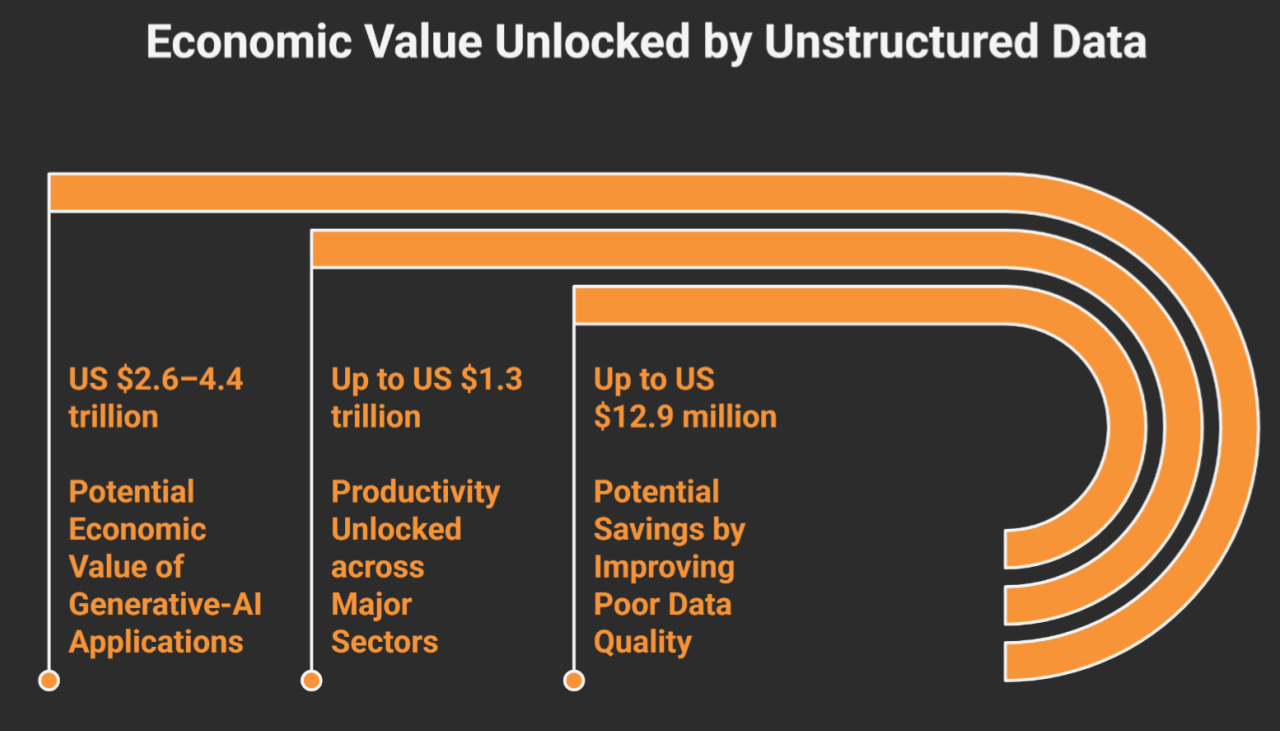
When left ungoverned and unstructured, data can become a silent liability. Gartner estimates poor data quality costs firms $12.9 million per year. One-third of data breaches involve unmanaged “shadow” files, with average breach costs surpassing $4.88 million.
Yet with governance and context, that same content becomes a high-yield asset. McKinsey estimates that generative-AI systems trained on well-labeled unstructured data could generate between $2.6 to $4.4 trillion in annual value.
Strategic Value Proposition
The benefits are immediate across functions. Product teams mine feedback from calls and community posts to build roadmaps informed by real user needs. Forrester links this approach to 41% faster revenue growth and 49% higher profit.
Meanwhile, tagging reviews and social chatter turns public content into competitive radar, often weeks ahead of structured KPIs. McKinsey finds that making unstructured content searchable can reclaim 20 to 25% of knowledge-worker time, freeing teams from manual searching.
Compliance teams benefit too. Classifying content in place allows firms to flag and act on risky data before regulators or attackers do. This act alone can potentially cut breach costs by over $2 million per incident.
Intelligence Evolution Framework
The shift unfolds in stages. NLP and computer vision transform scattered files into metadata-rich records. Pattern-recognition models flag early risk signals buried in text. Centralized classifiers push intelligence across systems, from data lakes to vector databases, to activate a single, governed source of truth.
The result: smarter decisions, faster action, and reduced exposure, all powered by content once treated as clutter.
Implement Advanced Data Classification Systems
Unstructured data holds value, but only when it can be interpreted and acted on. Classification turns disorganized content into structured, machine-readable inputs. It organizes files, emails, transcripts, and documents in ways that analytics platforms, compliance systems, and AI models can confidently use.
Without classification, unstructured content remains hidden. It cannot be governed or analyzed. However, it becomes a core part of the enterprise intelligence layer once properly labeled and structured.
Cognitive Classification Architecture
Classifying a file by type or title rarely captures its real purpose. Intent-based classification goes further by identifying what the document is actually doing. A vendor contract under negotiation is recognized for its content and role, not for how it is saved or named.
Entity extraction adds important detail. With natural language processing techniques like named entity recognition, systems can identify and pull out names, dates, monetary figures, and other relevant markers. This turns isolated files into structured data points connected to business processes.
Classification systems must evolve to keep pace with changing content. Adaptive taxonomies supported by large language models allow categories to adjust automatically. The model refines its labels as new patterns emerge or business terms shift. This reduces the burden on teams and keeps classification relevant over time.
Deep Content Understanding
Labeling content is only the starting point. True value comes from understanding what that content means within its full context. Semantic fingerprinting supports this by generating vector-based representations that reflect meaning and intent, rather than relying on isolated keywords. This approach allows systems to group related documents, even when the language or phrasing differs.
Contextual retrieval builds on this foundation by improving how systems interpret ambiguous terms based on their surrounding content. Words like “Apple” can refer to a company or a fruit, depending on usage. Models trained on real-world examples learn to resolve these distinctions, ensuring that search and classification results remain relevant and precise.
In multilingual environments, alignment across languages becomes essential. Cross-language models ensure that similar ideas are recognized regardless of the language used. This consistency enables global teams to apply shared taxonomies, enforce governance policies, and retrieve critical information with confidence, no matter where or how it was created.
Intelligent Classification Workflow
Static classification systems lose relevance quickly in dynamic environments. To maintain accuracy over time, modern systems must be able to learn and adapt. Intelligent workflows support this by incorporating mechanisms for continuous improvement as new data is processed.
Progressive learning forms the foundation. As documents flow through the system, models refine their understanding based on updated inputs and changing content patterns. This allows classification rules to evolve without requiring manual reprogramming.
Not all outputs carry equal certainty. Confidence scoring helps identify low-confidence classifications and routes them for human review. These interventions are a part of the system’s learning loop. When feedback is applied, the model improves and future decisions become more accurate.
This iterative process turns classification into a responsive function rather than a static utility. Accuracy and consistency increase over time, and outputs become more aligned with how teams actually work. As a result, unstructured data shifts from being a burden to becoming a trusted source of operational insight.
Transforming Unstructured Data into Predictive Insights
Once unstructured content is classified and enriched, it becomes far more than stored information. With the right systems in place, organizations can start to surface patterns, explore causes, and model outcomes that guide smarter decisions.
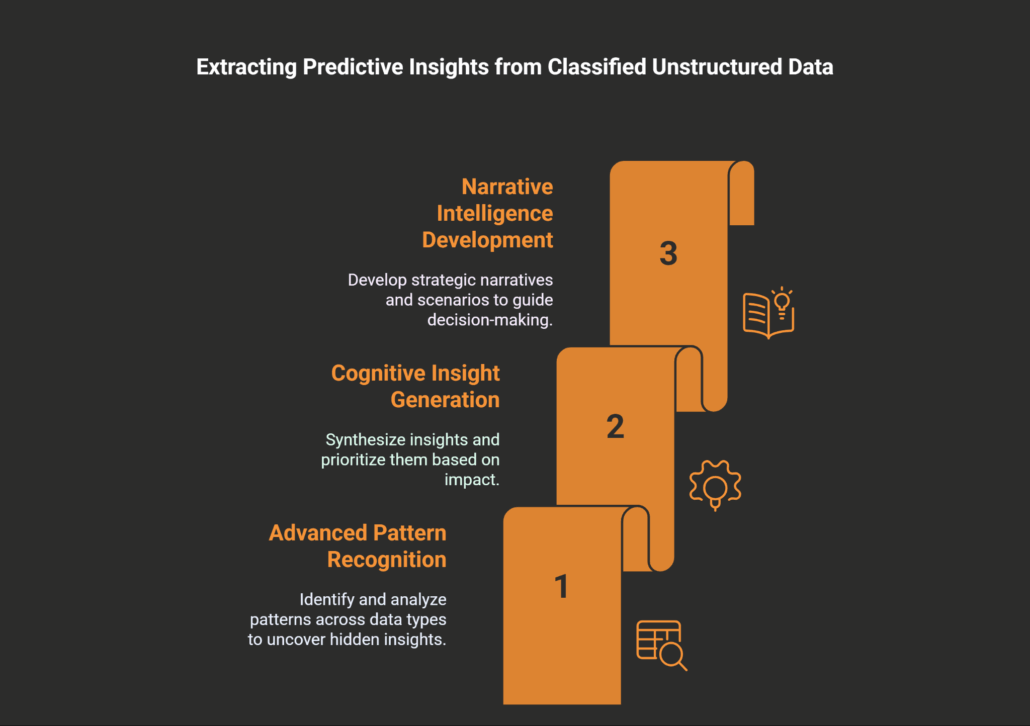
Advanced Pattern Recognition
Unstructured data reveals its value when recurring signals are identified and interpreted in context. Whether the input comes from text, audio, or scanned documents, these signals often contain the earliest indicators of change, provided the organization knows where to look.
The process begins with structure. Pattern recognition tools analyze unstructured inputs to uncover repetition, anomalies, or deviations. In written content, this may appear as recurring language linked to dissatisfaction or legal exposure. In audio recordings, tonal shifts and pacing changes can reflect rising frustration. In scanned files, inconsistent field usage or unusual clause pairings often signal non-compliance.
Context gives these signals meaning. Metadata such as customer role, communication channel, or journey stage helps systems distinguish between routine variation and issues that require escalation. For instance, a delay complaint from a new user holds different significance than the same comment from a long-term client. These contextual layers help models cluster similar cases and surface outliers.
After structural and contextual patterns are mapped, time adds another dimension. Temporal analysis shows how signals develop across days, weeks, or product cycles. An increase in support tickets may coincide with a recent update. A drop in engagement might align with a pricing change. Recognizing these sequences early allows teams to respond before issues become more difficult to reverse.
Behavioral sequence modeling adds further clarity. Isolated events often tell an incomplete story. But when actions like browsing help content, contacting support, and requesting a refund occur in sequence, they form a recognizable pattern. These sequences help teams identify dissatisfaction and predict churn before it appears in structured reports.
Cognitive Insight Generation
Recognizing a trend is useful, but understanding what triggered it creates real value. Automated hypothesis generation connects current shifts to possible causes based on past data. For example, a sudden increase in returns may relate to changes in packaging, delivery speed, or pricing structure.
When internal forecasts don’t align with external sentiment, contradiction detection helps surface the mismatch. Teams receive early signals that something may be off, even if metrics look steady. Business impact scoring helps focus attention on signals tied to revenue, risk, or retention.
Narrative Intelligence Development
Insights gain momentum when used to shape future action. Trend modeling allows teams to explore how current patterns may evolve. Strategic implication mapping connects those projections to business outcomes such as lost revenue or increased regulatory pressure.
Scenario modeling supports better planning. Teams simulate different responses and use past resolution data to anticipate consequences. Each cycle of insight builds on the last, helping organizations respond with clarity and plan with confidence.
Architect Robust Storage and Security Systems
Classifying unstructured content is an essential first step. But insight alone is not enough. Without the right infrastructure, valuable data remains vulnerable or inaccessible. To turn classification into real impact, organizations need systems that can protect sensitive content and keep intelligence flowing where it’s needed most.
Intelligent Content Management
Not every file is equally important. Yet many organizations store everything the same way, often without clear guidelines. Content-aware storage introduces a more intentional approach. Files that are used often, tied to regulatory obligations, or linked to high-value workflows remain prioritized. Those with low relevance are identified for archiving or flagged for review. This reduces clutter and lowers storage costs without sacrificing visibility.
Metadata is applied at the point of ingestion, assigning retention rules, classification labels, and access levels. These tags guide how each file is managed across its lifecycle, ensuring consistent handling from start to finish.
Adaptive Security Framework
Securing unstructured data requires more than perimeter controls. Content-aware security adapts to how data is used in real time. Behavioral analytics monitors usage patterns to detect anomalies. If a contractor accesses confidential records outside typical hours, the system can immediately flag the behavior and adjust permissions.
Access rights shift as context changes. Permissions are updated based on user role, device type, and data sensitivity to maintain both flexibility and control.
Privacy-Enhancing Technologies
Organizations can analyze sensitive data without exposing it. Techniques such as tokenization, field masking, and differential privacy enable the extraction of insights while preserving confidentiality. Consent tracking is built into the process, making it easier to align with evolving policies and regulations.
The result is a storage and security framework that does more than hold data. It turns unstructured content into governed, accessible, and trusted intelligence.
Build Intelligence-Ready Data Infrastructure
Security lays the groundwork, but infrastructure determines how far intelligence can go. Once unstructured content is structured and governed, it needs to reach the right people in the right format and at the right moment. But how does that happen at scale? What kind of system moves information from static storage to strategic use?
Intelligence Fabric Architecture
Traditional file systems were built for storage, not discovery. A knowledge graph changes that by organizing data through relationships instead of folders. Content is connected by meaning, not location, allowing teams to ask precise questions like, ‘Which clients had contract issues in Q1?’ and get a single, consolidated view drawn from emails, documents, and CRM records.
Multidimensional indexing adds further reach. Teams can search across formats, languages, and timeframes. Semantic search improves accuracy by interpreting intent, not just keywords, making it easier to find relevant content regardless of how it was written.
Cross-Silo Intelligence Integration
Insight loses value when it is stuck in isolated systems. A unified intelligence layer brings together data from across departments. Entity resolution helps by linking variations of a name or identifier, such as “J. Smith,” “John S.,” and “[email protected]” into a single profile. This reduces confusion and strengthens reporting.
When sources offer conflicting information, confidence scoring adds context. Teams can evaluate which signals are consistent and where further validation is needed. This helps guide action with greater certainty.
Intelligence Delivery Optimization
Intelligence only creates impact when it reaches the right people. Context-aware routing ensures insights are delivered based on role. Engineers receive alerts in technical systems. Executives see summaries connected to business outcomes. Dynamic packaging filters out excess and keeps the message clear.
In the end, intelligence should not sit idle. It should move through the organization with purpose, supporting decisions at every level.
Implement Intelligent Automation for Scaling
Even with classification, governance, and searchability in place, one problem continues to slow progress: timing. Insight that arrives too late cannot change outcomes. It only confirms what teams already know. In fast-moving environments, organizations need more than visibility. They need a way to act as soon as patterns appear. This is where automation becomes essential.
Deloitte reports that enterprises scaling intelligent automation reduce operational costs by 27% and increase workforce capacity by a similar margin. McKinsey finds that combining automation with AI improves productivity by 3.4% points yearly.
Cognitive Process Automation
Many document-heavy workflows still rely on manual handling. Whether it’s processing claims, reviewing contracts, or checking compliance, progress often relies on someone reading through and directing the files.
Automation changes that. Modern document understanding tools can now extract terms, values, dates, and intent directly from unstructured content. With the right systems in place, these insights are processed instantly, moving files into the correct workflow without delay.
When the system lacks confidence, it does not stop. It flags the content for review, learns from the correction, and improves with each iteration. Over time, this creates a feedback loop that gets smarter with use.
Autonomous Data Operations
Automation also works behind the scenes. Pipelines that feed analytics often break without warning. A format change or a delayed source can distort downstream output. Self-healing pipelines monitor data quality, detect issues in real time, and restore flow without human input.
Metadata is enriched throughout the process. This ensures that data lineage, compliance requirements, and quality indicators are tracked as content moves. Infrastructure-as-code allows these pipelines to be deployed consistently across the organization.
Intelligence Amplification Systems
Automation works best when paired with human judgment. Confidence scoring helps identify where expert input is needed. Scenario modeling allows teams to test what might have happened under different conditions. When experts step in, their input becomes part of the system’s memory, improving the model for the next decision.
As automation matures, organizations move faster with fewer resources. Teams spend less time chasing information and more time responding to what matters. However, to scale this across growing data environments, they need a platform that turns automation from a set of tools into an operational foundation.
Aparavi’s End-to-End Unstructured Data Solution
Aparavi provides the infrastructure needed to manage, govern, and activate unstructured content at scale for organizations looking to move beyond isolated tools and manual workarounds. It turns raw content into operational intelligence that flows across teams and systems. Here’s how Aparavi supports the full unstructured data lifecycle from discovery to action:
Deep Content Understanding
Aparavi begins by helping teams understand what they have, without moving or restructuring files.
- In-place indexing across 1,600+ file types: Content is analyzed in its original location, reducing migration risks and minimizing disruption.
- OCR-powered parsing and pattern recognition: Text, images, scanned documents, and logs are processed for meaning, exposing insights that standard tools often miss.
- Automated identification of sensitive or redundant content: Duplicate contracts, outdated records, and regulated files are flagged immediately, helping teams prioritize cleanup and compliance.
Intelligent Automation
Once content is understood, Aparavi makes it actionable through intelligent, policy-driven workflows.
- Real-time enforcement of data policies at detection: Files containing PII, expired agreements, or policy violations are automatically quarantined, encrypted, or deleted.
- Visual workflow builder with API extensibility: Teams can design automation flows through a drag-and-drop interface or connect directly to existing systems using API.
- Feedback-driven learning loop: Low-confidence files are sent for review, with human input improving system accuracy over time.
Comprehensive Governance
Aparavi enables consistent policy enforcement across complex environments.
- Centralized policy management across cloud, on-prem, and SaaS: Retention, encryption, and classification rules apply uniformly, reducing fragmentation in data governance.
- Reusable policy templates for scalable enforcement: Governance settings can be shared across departments or regions to streamline compliance efforts.
- On-the-fly re-evaluation of governed content: When policies change, the system rescans and updates affected files to prevent compliance gaps.
Scalable Intelligence Framework
Aparavi prepares unstructured content for downstream search, analytics, and AI applications.
- Native support for vector embeddings: Files are converted into structured, machine-readable vectors compatible with platforms like Milvus, Qdrant, and Weaviate.
- Pipelines for semantic search and Retrieval-Augmented Generation: Documents are chunked, enriched, and routed to tools that support intelligent search and question-answering workflows.
- Transformation of legacy file shares into searchable knowledge systems: Static repositories become structured, searchable data assets, ready to power assistants, regulatory review, and enterprise-wide discovery.
Final Takeaway
Unstructured data is expanding across every part of the enterprise. Contracts, emails, scanned documents, transcripts, and logs now account for the majority of business content. Yet for many organizations, the real challenge is not the volume of unstructured data but the lack of visibility.
Organizations need a solution that allows them to classify, govern, and activate unstructured data through intelligent infrastructure. They want it to become a source of real-time insight, operational precision, and AI-ready input.
Aparavi delivers the foundation to do just that. From policy enforcement to semantic readiness, its platform delivers end-to-end visibility, automates action at scale, and prepares data for AI without requiring a rebuild of your infrastructure.
To see how your data stacks up, start for free or speak with our experts.

