
The VertexAI connector integrates Google Cloud’s powerful large language models into your Aparavi workflow. This documentation helps you understand how to use and configure the VertexAI node effectively. This is typically used for tasks such as reasoning, summarization, content generation, and conversational response.
Key capabilities:
- Natural language understanding and generation
- Multimodal processing (text, images, audio, video)
- Reasoning and problem-solving
- Content summarization and transformation
- Conversational AI responses
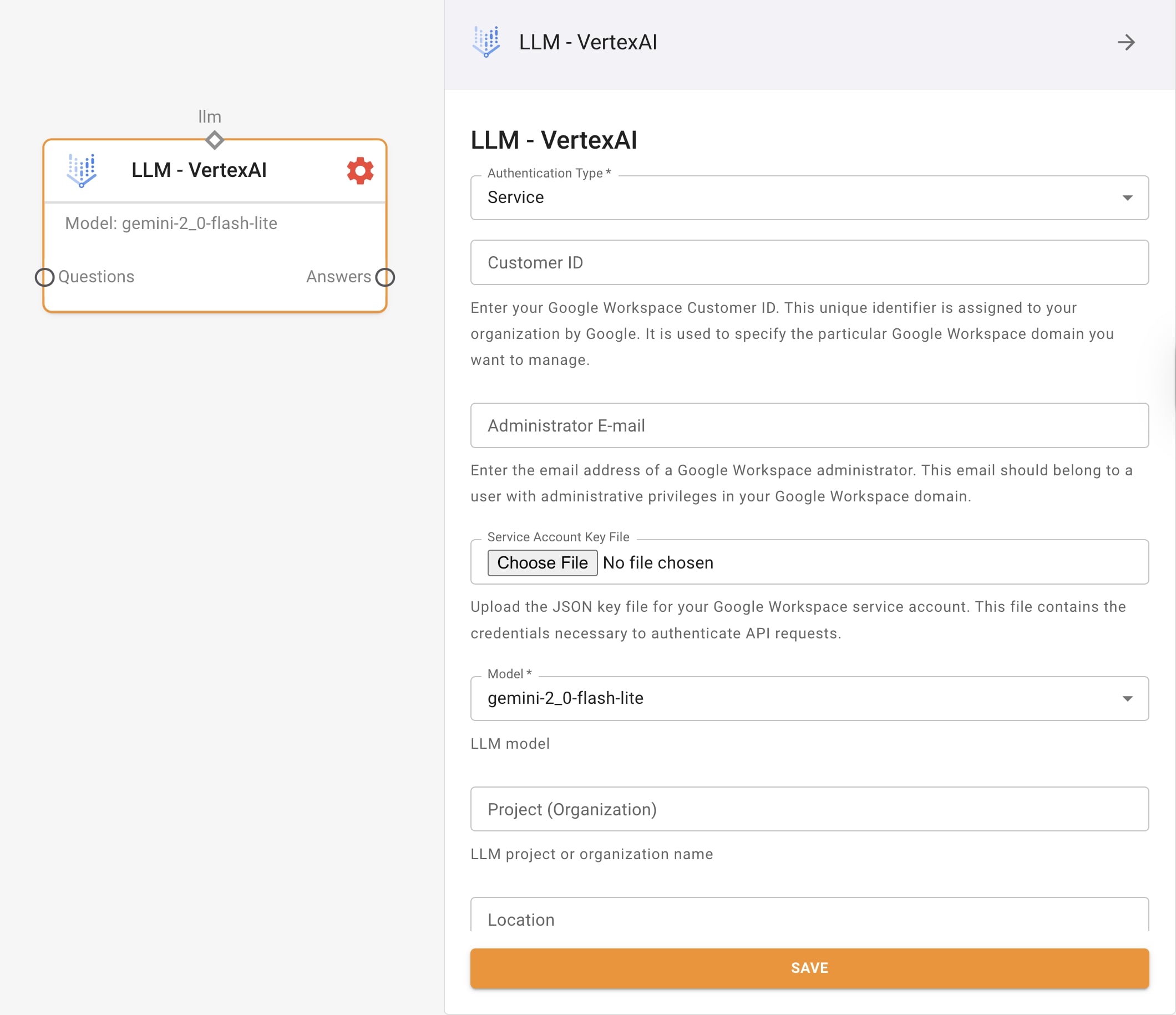
Configuration:
When setting up the VertexAI node, you’ll need to configure several parameters:
- Model Selection: Choose the appropriate model variant based on your needs
- Project ID: Enter your Google Cloud project ID
- Service Account JSON: Provide service account credentials
- Region: Specify Google Cloud region
Inputs and Outputs
Input Channels
- Prompt: Primary text input for the model
- Questions: Structured query inputs
- Documents: Content for context (PDFs, images)
- System: System-level instructions to guide model behavior
Output Channels
- Text: Generated text responses
- Answers: Structured response outputs
Supported Model Variants:
| Model Family & ID | Input Tokens (Context Window) | Output Token Limit | Input Modalities | Output Modalities | Notes / Status |
|---|---|---|---|---|---|
Gemini 2.5 Pro(gemini-2.5-pro) |
1,048,576 | ~65,536 | Text, Image, Audio, Video, PDF | Text | Deep think mode, function‑calling (GA) (Google Cloud,Google Cloud) |
Gemini 2.5 Flash(gemini-2.5-flash) |
1,048,576 | ~65,536 | Multimodal | Text | High throughput & cost‑effective (GA) (Google Cloud) |
Gemini 2.5 Flash‑Lite(gemini-2.5-flash-lite) |
1,048,576 | ~65,536 | Multimodal | Text | Preview; fastest variant in 2.5 family (Google Cloud) |
Gemini 2.0 Flash(gemini-2.0-flash) |
1,048,576 | ~8,192 | Multimodal | Text | GA; legacy regularly supported (Google Cloud) |
Gemini 2.0 Flash‑Lite(gemini-2.0-flash-lite) |
1,048,576 | ~8,192 | Multimodal | Text | Cost‑efficient variant (GA) (Google Cloud) |
Claude 3.5 Sonnet(claude‑3‑5‑sonnet) |
~200,000 | ~8,000 | Text, image (PDF via upload) | Text | Partner model via Model Garden; requires enabled access (Google Cloud) |
| Gemma 3(open; 1B/4B/12B/27B) | ~131,072 (128K) | ~8K–16K+ | Text, Image | Text | Multilingual & long‑context open LLM (Google Cloud) |
| Gemma 2 / variants(PaliGemma, CodeGemma, TxGemma, ShieldGemma 2) | ~128K | ~8,000 | Text (variant-specific multimodal) | Text | Specialized open models in Model Garden (Google Cloud) |
DeepSeek R1(deepseek‑ai/DeepSeek‑R1‑Distill‑Qwen‑32B) |
~128,000 | ~8,000 | Text | Text | Available via Model Garden partnership (Google Cloud) |
| Imagen 3(for Generation / Editing / Fast) | — (image‑prompt-to-image) | — (image generation) | Text prompts (and masks/images) | Images | GA via Model Garden (Google Cloud) |
| Veo 3&Veo 3 Fast(video generation) | — (text/image prompt) | — (video output) | Text + optional images | Video (1080p) | Veo 3 FAST & full version in GA/Preview (July 2025) (Google Cloud) |
Key Use Cases:
- Content Generation: Create drafts, summaries, and reports from structured data
- Data Analysis: Extract insights and identify patterns in unstructured text
- Conversational AI: Build chatbots and virtual assistants
- Document Processing: Analyze, summarize and extract information from documents
Frequently Asked Questions:
- Authentication: Verify credentials and IAM permissions; ensure region availability
- Performance: Implement back-off for rate limits; adjust timeouts for large contexts
- Response Quality: Refine prompts; adjust temperature and token settings as needed
- Cost Optimization: Select appropriate model variants based on complexity requirements