
This example is of a streamlined pipeline for text classification and anonymization before embedding. This integrated workflow intelligently categorizes content and removes personally identifiable information (PII) from text data, ensuring both regulatory compliance and data privacy while preparing it for optimal vector embedding and retrieval in AI applications.
Tutorial Video
Pipeline Overview
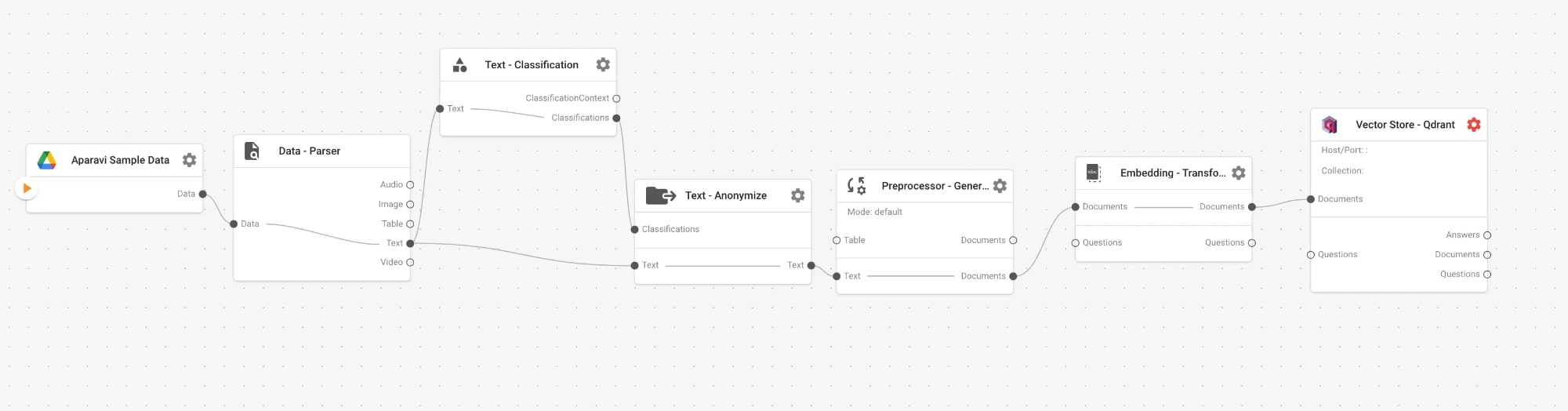
This is a Classification and Anonymization pipeline that processes text for privacy and categorization before embedding.
| Node | Function |
|---|---|
| Chat Input | Accepts user text input from chat interface |
| Parser | Extracts plain text from the input |
| Text Classification | Categorizes text into predefined classes/labels |
| Text Anonymizer | Removes or masks personally identifiable information (PII) |
| Preprocessor – General Text | Cleans and splits text into appropriate segments |
| Embedding – Transformer | Converts processed text into vector embeddings |
Key Capabilities:
- Multi-class Classification: Categorizes text into multiple predefined categories, enabling content routing and specialized processing.
- PII Detection & Masking: Identifies and anonymizes personal information, ensuring compliance with privacy regulations.
- Configurable Chunking: Splits text into optimally sized segments, improving retrieval precision and relevance.
- Vector Transformation: Converts text to semantic embeddings, enabling meaning-based search and retrieval.
Workflow Breakdown:
1. Data Source Node
This node pulls your source files (e.g., Google Drive, S3, local docs).
How it works
(e.g., Google Drive)
-
- Click ▶️ on the Aparavi Sample Data node. You’ll see two options in the Files section.
- The node fetches files from the configured drive path when you select ‘Preselected Data Sets.’
- If you select ‘Custom Data sets,’ you’ll need to provide the sample data path in the text box.
- Learn more about the Google Drive source node here: link
2. Data Parser Node
In this node, we extract the content from the files. In this scenario, we are extracting text.
How it works
- Receives “Data” from the Sample Data node.
- Splits into multiple channels: Text, Table, Image, Audio, Video.
3. Text Classification Node
Analyzes and categorizes text into predefined classes or categories.
How it works
- Processes text using a machine learning model to identify content categories.
- Assigns one or more classification labels to the text.
- Provides confidence scores for each classification.
Configuration:
- Text classification helps identify content types for appropriate processing and handling. The configuration interface for a text classification node in a data processing pipeline. This interface allows users to select various classification categories related to sensitive information policies in the United States, the US health, and Germany.

4. Text Anonymizer Node
The Text Anonymizer node identifies and masks personally identifiable information (PII) in text to ensure privacy and compliance.
How it works
- Scans text for PII such as names, emails, phone numbers, addresses, etc.
- Replaces identified PII with generic tokens or masks.
- Preserves the semantic structure of the text while removing sensitive data.
Configuration:

| Field | Example Value | Description |
|---|---|---|
| PII Types to Detect | Names, Emails, Phone Numbers, Addresses | Categories of PII that will be identified and masked |
| Anonymization Method | Token Replacement | How PII is masked (e.g., with generic tokens or asterisks) |
| Custom Entities | Company-specific terms | Additional entity types to anonymize beyond standard PII |
5. Preprocessor – General Text
The Preprocessor – General Text node splits large text blocks into smaller “documents” ready for embedding. Here, we’ll take the large text segments and split them up into documents that can be embedded.
How it works
- Takes parser output, applies sanitization, chunking, and metadata tagging.
- Emits a stream of document objects.
Configuration:
It ensures that our documents are split into well-sized, context-preserving segments, optimizing them for embedding and retrieval in your RAG pipeline.

| Setting | Value/Option | Description |
|---|---|---|
| Text Splitter | Default Text Splitter | Balances structure and size for general-purpose use |
| Split by | String length | Splits text based on character count |
| String Length | 512 | Each segment is up to 512 characters long |
Text Splitter

6. Embedding – Transformer
The Embedding – Sentence Transformer node is responsible for converting text (such as document segments or user questions) into vector embeddings, which are essential for semantic search and retrieval in a RAG pipeline.
How it works
Documents transformer:
turns each text chunk into a vector.
Configuration:
Available Options:
- Custom model: Use your own pre-trained or fine-tuned model.
- miniAll: A general-purpose model, suitable for a variety of tasks.
- miniLM: Optimized for general use, offering a good balance between performance and speed.
- mpnet: Another high-quality model, often providing strong results on semantic similarity tasks.

7. Vector Store (Qdrant) Node
The Qdrant Vector Store node is critical in a RAG pipeline. It is responsible for storing and retrieving vector embeddings, enabling efficient semantic search and context retrieval for downstream language models.
How it works
- Ingests document embeddings + metadata.
- On query, it computes similarity between the question vector and stored vectors.
- Returns top-K relevant document segments.
Configuration:

| Field | Example Value | Description |
|---|---|---|
| Type of Qdrant host | Your own Qdrant server | Specifies the Qdrant deployment (local, cloud, or custom server). |
| Host | localhost | The server address where Qdrant is running. |
| Port | 6333 | The port number Qdrant listens on (default: 6333). |
| Retrieval Score | Related | Sets the minimum similarity score for retrieving relevant vectors. |
| Collection | APARAVI | The name of the Qdrant collection used to store and query vectors. |
Hit the Play Button ▶️
Common Use Cases:
-
Healthcare Data Processing:
Healthcare organizations can use this pipeline to process patient records, ensuring PHI compliance by anonymizing sensitive information before embedding for AI analysis.
-
Legal Document Analysis:
Law firms can process case documents, automatically classifying content by legal domain while removing client identifiers to maintain confidentiality.
-
Financial Services:
Banks and financial institutions can process customer communications, removing account details and personal information while preserving the semantic meaning for trend analysis.
-
Customer Support:
Support teams can process ticket data to build knowledge bases while ensuring customer information is properly anonymized before embedding.
Frequently Asked Questions:
-
What PII types are detected?
Standard detection includes names, addresses, phone numbers, emails, SSNs, and credit card numbers. Custom entities can be added.
-
How accurate is the classification?
Accuracy depends on the model used and training data. Adjust confidence thresholds to balance precision and recall.
-
Can I preserve the original text alongside anonymized versions?
Yes, configure the anonymizer to output both original and anonymized versions, but ensure proper access controls.